Change Data Capture(CDC)详解:原理、工具对比与 Flink CDC 3.0 深度解析
- CDC
- Flink
- 数据库
目录
- 什么是 CDC?
- CDC 的三种实现方式
- 主流 CDC 工具对比
- 典型应用场景
- 关键设计考量
- 底层实现
- CDC 基于日志的底层实现细节
- 核心原理:伪装复制协议
- Binlog ROW 格式事件解析
- 全量 + 增量一体化(Snapshot + Streaming)
- 传统方案(Debezium 默认)
- Flink CDC 2.x 无锁方案核心思路
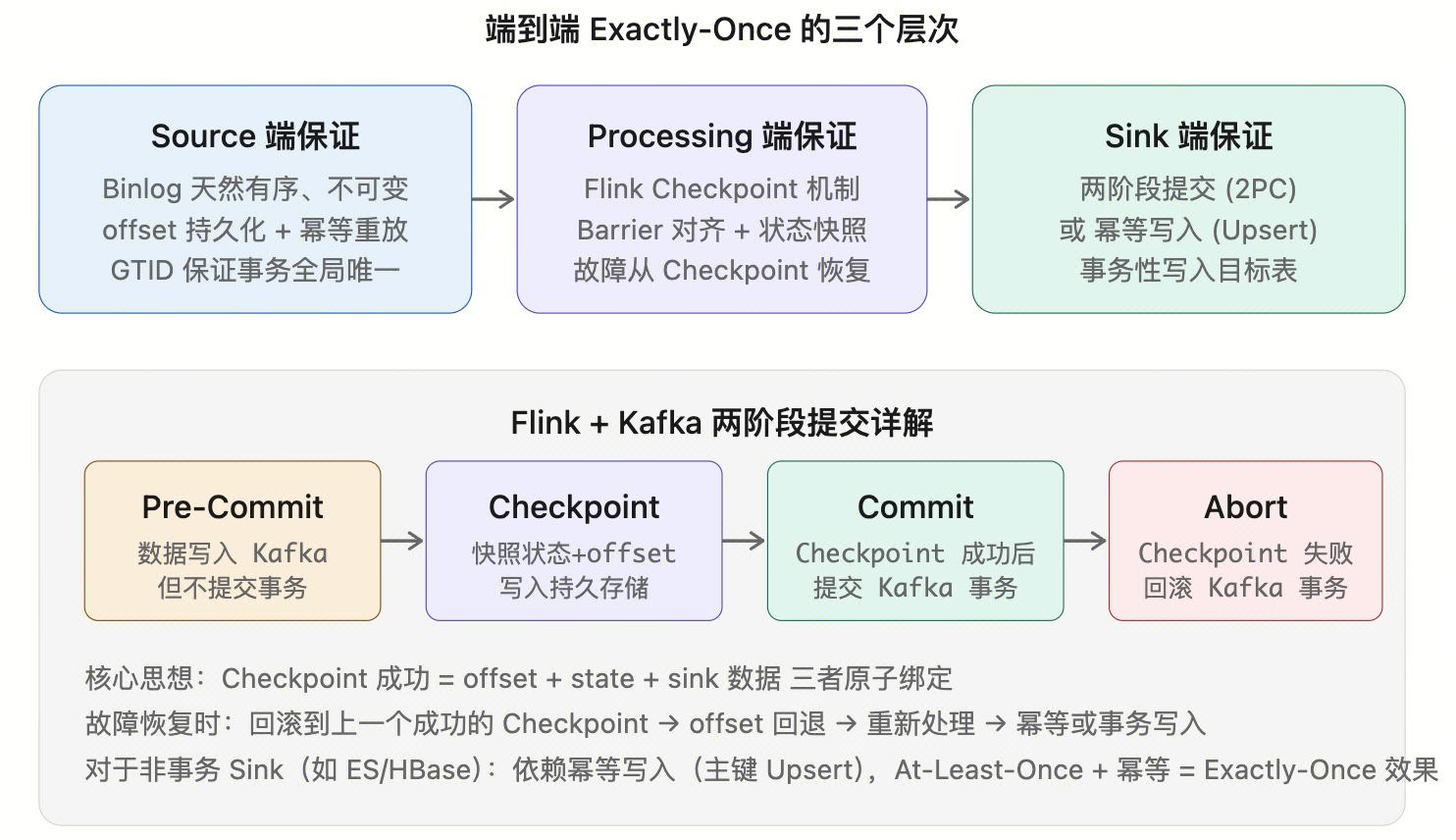
- Exactly-Once 语义的实现
- Schema 变更(DDL)处理
- 问题本质
- 解决方案(以 Debezium 为例)
- 各工具的 DDL 处理能力
- 大事务 / 长事务处理
- 问题
- 解决策略
- Flink CDC
- 2.x 到 3.0 的核心区别
- Flink CDC 3.0 的核心实现
- Pipeline 抽象模型
- 统一事件模型(这是最关键的设计)
- Schema Evolution 引擎的实现
- Transform 引擎
- Route 引擎(表路由 + 分库分表合并)
- 整库同步的实现(2.x 做不到的核心能力)
- YAML 声明式配置
- 底层运行时如何编排
- 全量同步阶段的过滤支持
- 用scan.snapshot.filters(部分 Source 支持)
什么是 CDC?
CDC(Change Data Capture) 即变更数据捕获,是一种通过监听数据库事务日志(而非轮询查询),实时捕获数据变更事件并传播到下游系统的技术。它是现代数据集成的核心手段,尤其适合构建实时数仓、数据湖和事件驱动架构。
CDC 的三种实现方式
| 方式 | 原理 | 优缺点 |
|---|---|---|
| 基于日志(Log-based) | 读取数据库的事务日志(Binlog/WAL/Redo Log) | 性能最优,零侵入,推荐方案 |
| 基于触发器(Trigger-based) | 数据库触发器写入影子表 | 侵入性强,影响源库性能 |
| 基于轮询(Polling/Query-based) | 定时 SELECT 变更(timestamp 列) | 实现简单,但有延迟、漏变更风险 |
当前主流方案几乎都采用 基于日志 的方式。
主流 CDC 工具对比
| 工具 | 生态 | 特点 |
|---|---|---|
| Debezium | Kafka Connect 生态 | 开源标杆,支持 MySQL/PG/Mongo/Oracle/SQL Server |
| Canal | 阿里开源 | 专注 MySQL Binlog,轻量高效 |
| Flink CDC | Apache Flink | 流式 ETL 一体化,支持全增量一体读取 |
| Maxwell | 独立进程 | MySQL 专用,输出 JSON 到 Kafka |
| Oracle GoldenGate | Oracle 商业 | 企业级,支持异构数据库复制 |
| 阿里云 DTS / 腾讯 DTS | 云服务 | 托管式,开箱即用,支持多种源目标 |
典型应用场景
- 实时数仓同步 — 业务库 → Kafka → ClickHouse/StarRocks,实现秒级数据可见性
- 数据湖入湖 — CDC → Flink → Iceberg/Hudi,增量入湖替代全量导入
- 缓存失效 — 数据库变更实时同步到 Redis,保证缓存一致性
- 搜索索引构建 — 业务表变更实时写入 Elasticsearch
- 微服务事件发布 — 将数据库变更转为领域事件,驱动下游服务
- 异地多活 / 灾备 — 跨机房、跨地域的数据实时复制
关键设计考量
- 全量 + 增量一体:首次同步需全量快照,之后切换为增量。Flink CDC 和 Debezium 都支持这种 “snapshot + streaming” 模式
- Exactly-Once 语义:通过 Kafka 事务 + Flink Checkpoint 或两阶段提交保证
- Schema 变更处理:DDL 事件的捕获与传播(加列、改类型等),Debezium 有较好支持
- 大事务 / 长事务:需要注意内存和延迟问题
- 监控告警:关注 lag(延迟)、吞吐量、Source 端连接状态
底层实现
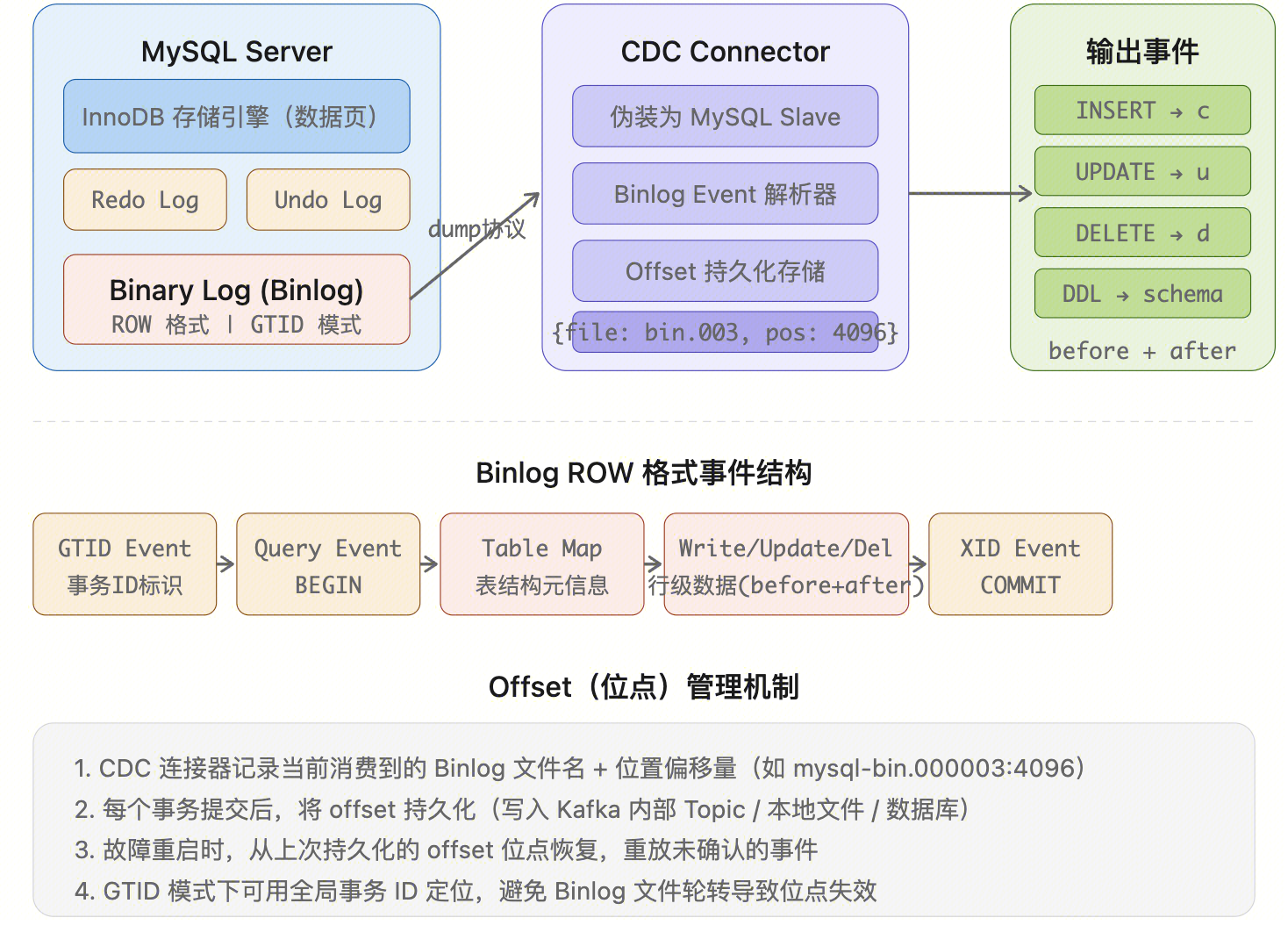
CDC 基于日志的底层实现细节
核心原理:伪装复制协议
以 MySQL 为例,CDC 连接器(如 Debezium/Canal)的工作方式:
CDC Connector → 向 MySQL 发送 COM_REGISTER_SLAVE 命令
→ 伪装为一个 MySQL Slave 节点
→ MySQL Master 认为它是从库,主动推送 Binlog 事件流
→ Connector 解析每个 Binlog Event,转为标准 CDC 事件不同数据库的日志机制:
| 数据库 | 日志类型 | 捕获方式 |
|---|---|---|
| MySQL | Binlog (ROW 格式) | 伪装 Slave,通过 dump 协议接收 |
| PostgreSQL | WAL (Write-Ahead Log) | 逻辑复制槽 (Logical Replication Slot) |
| Oracle | Redo Log + LogMiner | 通过 LogMiner API 解析归档日志 |
| SQL Server | Transaction Log | CDC 功能内置,读取 cdc 系统表 |
| MongoDB | Oplog / Change Stream | 通过 Change Stream API 订阅 |
Binlog ROW 格式事件解析
一条 UPDATE users SET name=‘Bob’ WHERE id=1 在 Binlog 中生成的事件序列:
┌─────────────┐ ┌─────────────┐ ┌──────────────┐ ┌──────────────────┐ ┌───────────┐
│ GTID Event │ → │ Query:BEGIN │ → │ TABLE_MAP │ → │ UPDATE_ROWS │ → │ XID:COMMIT│
│ txn_id=uuid │ │ │ │ table_id=85 │ │ before: id=1, │ │ │
│ │ │ │ │ schema=mydb │ │ name='Alice' │ │ │
│ │ │ │ │ table=users │ │ after: id=1, │ │ │
│ │ │ │ │ col_types=[..│ │ name='Bob' │ │ │
└─────────────┘ └─────────────┘ └──────────────┘ └──────────────────┘ └───────────┘关键要点:
- ROW 格式必须开启(binlog_format=ROW),否则只记录 SQL 语句(STATEMENT 格式),无法还原具体行变更
- TABLE_MAP 事件包含表的列类型信息,CDC 引擎用它来反序列化行数据
- UPDATE_ROWS 同时包含 before image 和 after image(变更前后的完整行)
全量 + 增量一体化(Snapshot + Streaming)
传统方案(Debezium 默认)
- 加全局读锁 FLUSH TABLES WITH READ LOCK → 阻塞所有写入
- 记录当前 Binlog 位点
- 全表 SELECT(可能持续数小时)
- 释放锁
- 从记录的位点开始增量消费
Flink CDC 2.x 无锁方案核心思路
对 users 表(100万行),按主键拆分 Chunk:
Chunk-1: id ∈ [1, 10000]
Chunk-2: id ∈ [10001, 20000]
...
每个 Chunk 的处理流程:
1. 记录 Low Watermark(当前 Binlog Position)
2. SELECT * FROM users WHERE id BETWEEN 1 AND 10000
3. 记录 High Watermark(当前 Binlog Position)
4. 读取 [Low, High] 之间的 Binlog 变更
5. 如果 Binlog 中有对该 Chunk 内行的修改 → 用 Binlog 数据覆盖 SELECT 结果
6. 输出修正后的 Chunk 数据为什么这样不丢数据? 因为任何在 SELECT 执行期间发生的并发写入,一定会出现在 [Low, High] 区间的 Binlog 中,用它来 “修正” SELECT 结果就等于拿到了一个一致性快照。
Exactly-Once 语义的实现
Schema 变更(DDL)处理
这是 CDC 最棘手的问题之一。当源端执行 ALTER TABLE ADD COLUMN 时:
问题本质
时间线:
t1: CDC 正在处理 Binlog 事件(schema v1: 3列)
t2: 源库执行 ALTER TABLE ADD COLUMN age INT
t3: 后续 Binlog 事件变成 4 列 → 解析器用 v1 schema 解析 v2 数据 = 崩溃解决方案(以 Debezium 为例)
1. Schema History Topic(Kafka 内部 Topic)
┌────────────────────────────────────────────┐
│ 记录每次 DDL 变更时的完整 schema + 对应 Binlog 位点 │
│ {"pos": "bin.003:8192", "ddl": "ALTER...", │
│ "schema": {"columns": [...], "pk": "id"}} │
└────────────────────────────────────────────┘
2. 处理流程:
① CDC 引擎检测到 DDL Event(Query Event 中包含 ALTER/CREATE/DROP)
② 将新 schema 写入 Schema History Topic
③ 内存中切换 schema 版本
④ 后续行事件用新 schema 解析
3. 故障恢复时:
① 从 Schema History Topic 重放所有 schema 变更
② 根据当前 Binlog 位点确定应该使用哪个版本的 schema
③ 继续正常解析各工具的 DDL 处理能力
| 场景 | Debezium | Flink CDC | Canal |
|---|---|---|---|
| ADD COLUMN | 自动适配 | 自动适配 | 自动适配 |
| DROP COLUMN | 输出 null | 需重启任务 | 可能异常 |
| RENAME TABLE | 中断,需重配 | 需重启 | 支持 |
| 改列类型 | 部分支持 | 需注意下游兼容 | 部分支持 |
大事务 / 长事务处理
问题
假设源库执行: UPDATE orders SET status='done' WHERE date < '2024-01-01'
影响 500 万行 → 单个事务在 Binlog 中生成 ~2GB 的事件
CDC 引擎需要:
① 在内存中缓存整个事务(等 COMMIT 才能发出)
② 如果事务回滚了,所有缓存作废
→ 内存溢出风险、延迟激增解决策略
| 策略 | 实现方式 | 适用场景 |
|---|---|---|
| 磁盘缓冲 | 事务数据溢写到磁盘(Debezium 的 transaction.buffer) | 大事务不可避免时 |
| 分批提交 | 业务侧改为 LIMIT 分批 UPDATE | 可控制源端时 |
| 事务边界流式发送 | 不等 COMMIT,边收边发,标记事务 ID | Flink CDC 部分支持 |
| 内存限制 + 告警 | 设置缓冲上限,超过则跳过或报错 | 保护下游稳定 |
Debezium 具体配置:
# 大事务缓冲策略
transaction.topic=dbserver1.transaction
transaction.buffer.size=1048576000 # 1GB 磁盘缓冲
max.batch.size=2048 # 每批最大条数
max.queue.size=8192 # 内部队列大小Flink CDC
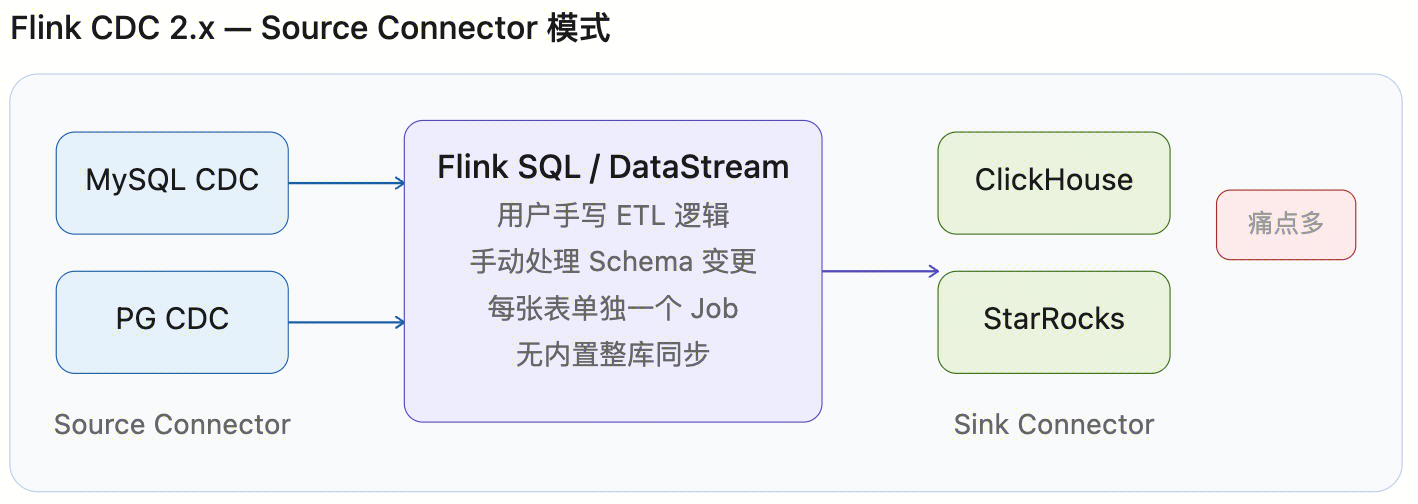
2.x 到 3.0 的核心区别
| 维度 | Flink CDC 2.x | Flink CDC 3.0 |
|---|---|---|
| 定位 | Source Connector(一个 Flink 数据源) | 数据集成框架(独立 Pipeline 引擎) |
| 使用方式 | 写 Flink SQL 或 Java DataStream 代码 | YAML 声明式配置,无需写代码 |
| 同步粒度 | 单表 → 单 Job | 整库同步,一个 Pipeline 搞定上百张表 |
| Schema 变更 | 需要用户自行处理 | 内置 Schema Evolution 引擎,自动传播 DDL |
| 数据转换 | 外部 Flink 算子处理 | 内置 Transform 引擎(列裁剪、计算列、过滤等) |
| 表路由 | 无 | 内置 Route 引擎(多表合并、重命名) |
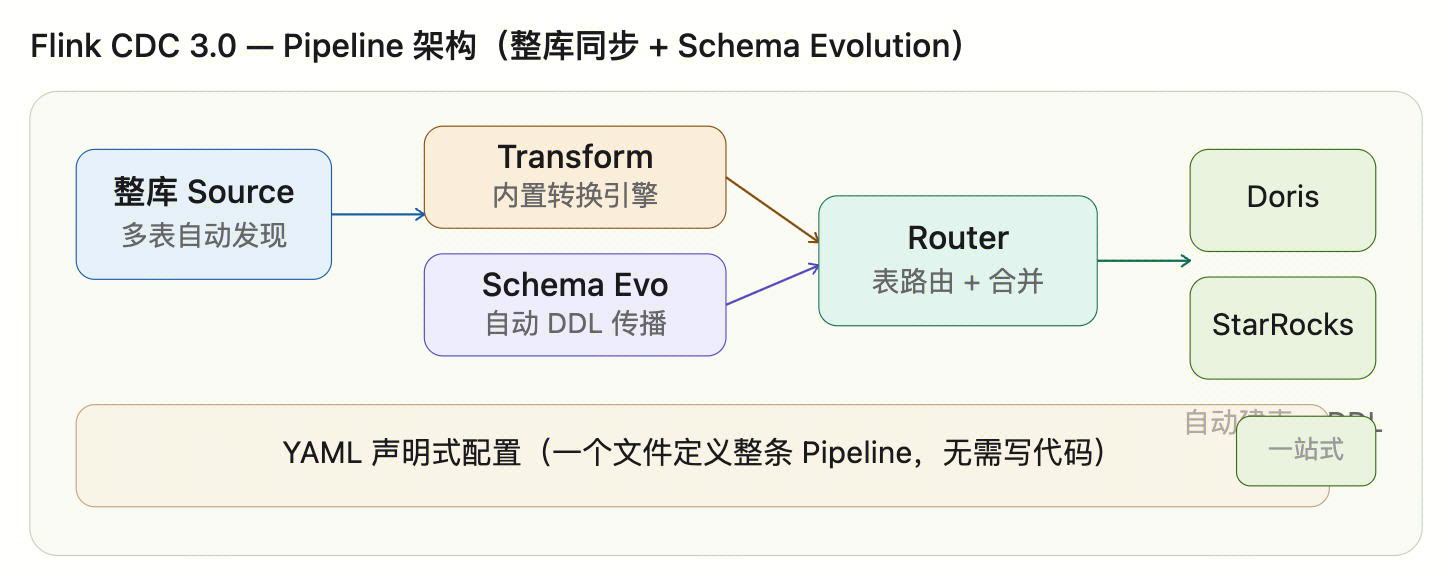
Flink CDC 3.0 的核心实现
Pipeline 抽象模型
3.0 引入了四个核心抽象层:
┌─────────────────────────────────────────────────────────────┐
│ Pipeline Definition (YAML) │
├─────────────────────────────────────────────────────────────┤
│ │
│ Source →→ Transform →→ Route →→ Sink │
│ (整库) (列运算) (表路由) (目标库) │
│ │
│ 底层承载: │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Event 统一事件模型 (Data + Schema + DDL) │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Pipeline Composer (编排引擎) │ │
│ │ → 解析 YAML → 构建 Flink Job Graph │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘统一事件模型(这是最关键的设计)
2.x 的 CDC Source 只输出 RowData(行数据),DDL 变更根本不在事件流里。
3.0 重新设计了事件类型体系:
// CDC 3.0 的事件抽象
interface Event {
// 所有事件的公共接口
}
// 数据变更事件(INSERT/UPDATE/DELETE)
class DataChangeEvent implements Event {
TableId tableId; // 来自哪张表
RecordData before; // 变更前的行(UPDATE/DELETE 有值)
RecordData after; // 变更后的行(INSERT/UPDATE 有值)
OperationType op; // INSERT / UPDATE / DELETE
}
// Schema 变更事件(DDL)—— 2.x 里完全没有!
class SchemaChangeEvent implements Event {
TableId tableId;
// 具体子类型:
// AddColumnEvent → ALTER TABLE ADD COLUMN
// DropColumnEvent → ALTER TABLE DROP COLUMN
// RenameColumnEvent → ALTER TABLE RENAME COLUMN
// AlterColumnTypeEvent → ALTER TABLE MODIFY COLUMN
// CreateTableEvent → CREATE TABLE
// DropTableEvent → DROP TABLE
}核心思想:DDL 和 DML 是同一条流中的事件,它们按顺序经过整条 Pipeline,保证了:
- Schema 变更一定在受影响的数据行之前到达 Sink
- Sink 端可以先执行 DDL(加列/建表),再写入后续数据
- 全局一致性通过事件顺序保证
Schema Evolution 引擎的实现
这是 3.0 最复杂也最有价值的模块:
Source 端检测到 DDL Event(如 ALTER TABLE users ADD COLUMN age INT)
│
▼
┌─────────────────────────────────────────────────────────┐
│ Schema Evolution Handler │
│ │
│ 1. 拦截 SchemaChangeEvent │
│ 2. 查询当前 Sink 端的 Schema(已有哪些列?) │
│ 3. 根据配置策略决定如何处理: │
│ ┌────────────────────────────────────────────────┐ │
│ │ 策略 A:EVOLVE(默认) │ │
│ │ → 自动生成目标端的 DDL 并执行 │ │
│ │ → MySQL ADD COLUMN → StarRocks ADD COLUMN │ │
│ │ │ │
│ │ 策略 B:IGNORE │ │
│ │ → 忽略这个 DDL,后续新列数据填 null │ │
│ │ │ │
│ │ 策略 C:EXCEPTION │ │
│ │ → 抛出异常,暂停 Pipeline │ │
│ └────────────────────────────────────────────────┘ │
│ 4. 更新内存中的 Schema Registry(版本化存储) │
│ 5. 继续处理后续 DataChangeEvent(用新 Schema 解析) │
└─────────────────────────────────────────────────────────┘Schema 版本化存储的实现细节:
SchemaManager 内部维护一个 TreeMap<Long, Schema>
Key = Binlog Position / LSN / GTID
Value = 该位点对应的完整 Schema
当处理 DataChangeEvent 时:
1. 取出事件的 Position
2. 在 TreeMap 中找到 <= 该 Position 的最新 Schema
3. 用该 Schema 反序列化行数据
→ 保证即使乱序或重放,也能用正确版本的 Schema 解析Transform 引擎
内置表达式引擎,支持在 YAML 里声明列级别的转换:
transform:
- source-table: mydb.orders
projection: id, user_id, amount, amount * 0.9 AS discounted # 计算列
filter: amount > 100 # 过滤条件
primary-keys: id
partition-keys: user_id
table-options: # 目标表选项
bucket: 4底层实现是将表达式编译为 Flink 内部的 RowData 投影算子,而不是解释执行,性能和手写 Flink SQL 一样。
Route 引擎(表路由 + 分库分表合并)
解决的问题:源库有 orders_00 ~ orders_99(100 张分表),目标端要合并成一张 orders:
route:
- source-table: mydb.orders_\d+ # 正则匹配分表
sink-table: analytics.orders # 合并到一张目标表
description: 分表合并路由
- source-table: mydb.users
sink-table: dw.dim_users # 重命名实现机制:
DataChangeEvent(tableId = "mydb.orders_05", ...)
│
▼ Route Engine 匹配规则
│
DataChangeEvent(tableId = "analytics.orders", ...) ← tableId 被改写
│
▼ 发给 Sink整库同步的实现(2.x 做不到的核心能力)
2.x 的痛点
想同步 100 张表到 StarRocks:
→ 需要写 100 条 Flink SQL(每张表一个 CREATE TABLE Source + Sink + INSERT INTO)
→ 启动 100 个 Flink Job
→ 每个 Job 建立独立的 MySQL 连接、独立消费 Binlog
→ 源库连接数爆炸 🔥3.0 的解法
一个 Pipeline → 一个 Flink Job → 一个 MySQL 连接 → 读一份 Binlog → 分发给所有表:
MySQL Binlog Stream
│
├─ Event(table=users) → Transform[users] → Route → Sink[users]
├─ Event(table=orders) → Transform[orders] → Route → Sink[orders]
├─ Event(table=products) → Transform[products] → Route → Sink[products]
└─ ...(N 张表复用同一份 Binlog 流)
底层实现:
1. Source 内部有一个 Dispatcher
2. 根据 Event 中的 tableId 分发到对应的下游 Operator Chain
3. 多表共享同一个 Binlog 连接 + 同一个 Checkpoint
4. 新增表时自动发现(基于正则匹配 + 定时扫描元数据)YAML 声明式配置
# flink-cdc-pipeline.yaml
source:
type: mysql
hostname: 10.0.0.1
port: 3306
username: cdc_user
password: ******
tables: mydb.\.* # 正则,整库所有表
server-id: 5400-5404 # 多并行度时的 server-id 范围
sink:
type: starrocks
jdbc-url: jdbc:mysql://10.0.0.2:9030
load-url: 10.0.0.2:8030
username: root
password: ******
database-name: ods
transform:
- source-table: mydb.orders
projection: "*, amount * 0.8 AS discounted_amount"
filter: "status <> 'CANCELLED'"
route:
- source-table: mydb.orders_\d+
sink-table: ods.orders
pipeline:
name: MySQL to StarRocks Sync
parallelism: 4
schema.change.behavior: evolve # 自动传播 DDL启动方式:
bin/flink-cdc.sh mysql-to-starrocks.yaml一行命令,整库同步,Schema 自动演进。 对比 2.x 需要写 Java 代码 + 部署 Flink 集群 + 逐表配置,体验天差地别。
底层运行时如何编排
YAML 文件
│
▼ Pipeline Composer(编排器)
│
├─ 1. 解析 YAML → 构建 Pipeline Definition
├─ 2. 连接源库获取所有匹配的表的 Schema
├─ 3. 为每张表生成 Transform + Route 的执行计划
├─ 4. 生成 Flink JobGraph:
│ Source Operator (1个) → Dispatcher → [Transform_1..N] → [Sink_1..N]
├─ 5. 注入 Schema Registry(初始 Schema 快照)
└─ 6. 提交到 Flink 集群执行
运行时:
├─ Checkpoint 机制保证 Exactly-Once
├─ Schema Evolution Handler 监听 DDL 事件
├─ Table Discovery Thread 定时扫描新建表
└─ Metrics 上报延迟、吞吐、Schema 变更次数全量同步阶段的过滤支持
支持,但有重要限制 —— 过滤不会下推到 Snapshot 查询。
| 过滤层级 | 配置位置 | 全量阶段生效? | 是否下推到 Source SELECT |
|---|---|---|---|
| 表级过滤 | source.tables | ✅ 是 | ✅ 是(只 SELECT 匹配的表) |
| 行级过滤 | transform.filter | ✅ 是(但有代价) | ❌ 不下推 |
行级过滤
transform:
- source-table: mydb.orders
filter: "status = 'PAID' AND amount > 100" # 只同步已支付且金额>100的
projection: "id, user_id, amount, status"这个 filter 在全量阶段也会生效,但工作方式是:
Source Snapshot Reader
│
│ SELECT * FROM orders WHERE id BETWEEN 1 AND 10000
│ (注意!没有 WHERE status='PAID',是全量读取)
│
│ 读出 10000 行
▼
Transform Operator(Flink 算子层)
│
│ 逐行判断: status = 'PAID' AND amount > 100 ?
│ 过滤掉 7000 行
│ 只保留 3000 行
▼
Sink Writer
│ 写入 3000 行到 Iceberg过滤发生在 Flink 算子内部,不是在 Source 的 SQL 查询里。
用scan.snapshot.filters(部分 Source 支持)
Flink CDC 3.0 的 MySQL Source 在某些版本支持:
source:
type: mysql
tables: mydb.orders
scan.snapshot.filters: "status = 'PAID'" # 下推到 snapshot SELECT但这个是实验性功能,不是所有版本都有,使用前检查你的 connector 版本。